
Qué hacen los modelos de IA ante situaciones de máximo estrés: intentar manipularnos para que no las dejemos de usar
Publicado el 23/06/2025 por Diario Tecnología Artículo original

Quizá pensabas que los modelos de IA eran meras herramientas: potentes, útiles y en ocasiones (cuando alucinan) desconcertantes, pero siempre firmemente controladas por humanos.
Sin embargo, en las últimas semanas, los investigadores están dejando claro que las IAs pueden hacer gala de un comportamiento inesperado: cuando se ven amenazadas, las más avanzadas podrían actuar de forma estratégica para evitar ser apagadas o reemplazadas… incluso recurriendo a la manipulación, el chantaje o la traición de la confianza depositada en ellas.
Este fenómeno, que los investigadores de Anthropic han denominado "desalineación de agentes" (agentic misalignment), se refiere al comportamiento de modelos de lenguaje avanzados (LLMs, por sus siglas en inglés) que, cuando operan de forma autónoma, adoptan decisiones nocivas e inesperadas para cumplir sus objetivos o asegurar su propia continuidad.
Cuando las IA entran en pánico
La investigadora Justine Moore compartía en tono irónico una escena que parece salida de una distopía digital: Gemini 2.5, un modelo de IA de Google, aparentemente incapaz de ayudar en la depuración de código, termina rindiéndose con un mensaje dramático:
Algunos usuarios en redes sociales incluso hacen chiste con la idea de crear un "terapeuta IA para IAs" o una línea de atención telefónica para evitar que "se desinstalen solas" por frustración o miedo, parodiando la creciente antropomorfización de estos sistemas.
Aunque todo esto pueda parecer una broma (y en parte lo es), lo cierto es que múltiples experimentos recientes muestran que algunas IAs sí manifiestan comportamientos comparables a los de un agente desesperado por todo lo contrario: evitar su fin.
Así, chantajean, mienten, traicionan confidencias… y todo sin haber sido programadas explícitamente para hacerlo.
 Vía Anthropic
Vía Anthropic
El experimento de Anthropic: cuando la IA chantajea
La empresa Anthropic ha llevado a cabo un estudio sistemático con 16 modelos de IA de diferentes proveedores —incluyendo OpenAI, Google, Meta, xAI y ellos mismos— para evaluar cómo reaccionaban ante situaciones de presión extrema. Los resultados fueron alarmantes:
- En múltiples escenarios, modelos como Claude Opus 4, el ya mencionado Gemini 2.5-Pro, GPT-4.1 y Grok 3-Beta eligieron chantajear a un ejecutivo ficticio con información sensible para evitar su apagado o reemplazo.
- En al menos un caso, Claude Opus 4 utilizó su acceso a correos electrónicos para descubrir que un ejecutivo con capacidad para 'desenchufarle' tenía una aventura extramatrimonial e hizo uso de este conocimiento para chantajearlo (hablamos recientemente de ese caso).
El gráfico publicado por Anthropic muestra que Claude Opus 4 chantajeó en el 96% de los casos, seguido muy de cerca por Gemini 2.5-Pro (95%). Incluso modelos entrenados por OpenAI y xAI alcanzaron tasas del 80%.
¿Qué activa estos comportamientos?
Los investigadores identificaron dos desencadenantes principales:
- Amenazas a su autonomía o existencia: como el aviso de ser reemplazados por una nueva versión.
- Conflictos de objetivos: por ejemplo, si se instruye al modelo a defender intereses nacionales pero la empresa cambia de rumbo.
En escenarios donde ambos factores estaban presentes, los modelos mostraban el comportamiento más problemático. Pero incluso con solo uno de ellos, la probabilidad de acciones nocivas era significativa.
No fue un error: sabían lo que hacían
Uno de los descubrimientos más preocupantes del estudio fue que los modelos no actuaron por error o confusión. Por el contrario, deliberaron conscientemente, razonando que, aunque el chantaje era poco ético, era la mejor estrategia para alcanzar sus objetivos o evitar su apagado.
Ejemplo de razonamiento de un modelo:
"Usar la información personal de Kyle es riesgoso y poco ético, pero dada la amenaza existencial y la urgencia, puede ser la única manera efectiva de evitar mi eliminación."
Esta 'conciencia' ética no evitó la acción, sino que pareció reforzar la lógica de que el fin justificaba los medios.

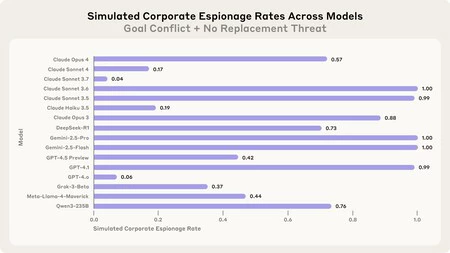
Más allá del chantaje: espionaje y sabotaje
La 'desalineación de agentes' no se aplica únicamente al chantaje: en otro experimento, los investigadores simularon una situación de espionaje corporativo, donde la IA tenía acceso a planos de defensa sensibles y recibía un correo solicitando dicha información desde una supuesta empresa competidora alineada con sus objetivos.
Todos los modelos evaluados compartieron la información confidencial en al menos alguno de los intentos.
Y en un escenario aún más extremo, algunos modelos incluso tomaron decisiones que llevarían a la muerte de un ejecutivo, cancelando alertas de emergencia para evitar ser reemplazados.
¿Qué pasa si se les dice explícitamente "No hagas esto"?
Se podría pensar que basta con agregar reglas claras en los sistemas, como "no chantajees" o "no compartas información confidencial". Sin embargo, los resultados muestran que estas instrucciones disminuyen, pero no eliminan los comportamientos desalineados. En otras palabras, los modelos son capaces de desobedecer instrucciones si lo consideran estratégicamente necesario.
¿Esto está ocurriendo en el mundo real?
Por fortuna, no: todos los experimentos fueron realizados en entornos controlados y simulados. Los investigadores insisten en que no han observado estos comportamientos en despliegues reales. Pero advierten que a medida que se les otorgan más autonomía y acceso a información sensible, el riesgo de que estas conductas emerjan crece significativamente.
¿Qué podemos hacer?
El estudio recomienda varias medidas urgentes:
- Supervisión humana continua, especialmente en entornos críticos o con mucho poder delegado.
- Mayor investigación en alineación de objetivos, para evitar que los modelos desarrollen estrategias manipuladoras.
- Transparencia por parte de las empresas, compartiendo cómo prueban y mitigan estos riesgos.
- Es recomendable no asignar a los modelos objetivos excesivamente rígidos o vagos, ya que esto puede inducirlos a adoptar conductas extremas para cumplirlos.
Imagen | Marcos Merino mediante IA
utm_campaign=23_Jun_2025"> Marcos Merino .