
Alibaba ha presentado su modelo IA más grande, con un billón de parámetros. La pregunta es si a estas alturas eso significa algo
Publicado el 09/09/2025 por Diario Tecnología Artículo original

El gigante chino Alibaba ha anunciado un nuevo modelo de lenguaje, el más grande que han anunciado hasta la fecha. Se llama Qwen-3-Max y presume de que cuenta con más de 1 billón de parámetros.
El más grande. Es el último modelo dentro de la serie Qwen3 que se lanzó en mayo de este año y, como su nombre 'Max' indica, es el más grande hasta la fecha. Su tamaño viene dado por los parámetros, 1 billón para ser exactos, mientras que los modelos anteriores de su serie llegaban a 235.000 millones como máximo. Según South China Morning Post (de quien es propietario Alibaba), su modelo destaca en comprensión del lenguaje, razonamiento y generación de texto.

Benchmarks. Los resultados de los benchmarks sitúan a Qwen3-Max por delante de competidores como Claude Opus 4, DeepSeek V3.1 y Kimi K2. Si no aparecen Gemini 2.5 Pro o GPT-5 es porque son modelos de razonamiento y sólo han comparado modelos de respuesta rápida. Tal y como señalan en Dev.to, tanto Gemini 2.5 Pro como GPT-5 obtienen puntuaciones superiores en matemáticas y código, por lo que los modelos de razonamiento siguen teniendo ventaja en esas áreas. Qwen3-Max-preview ya se puede probar de forma gratuita.
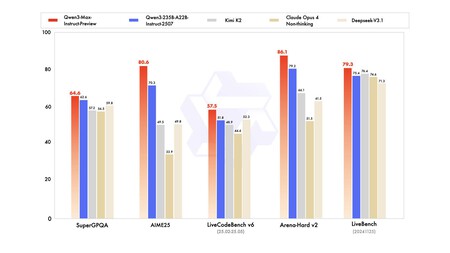 Benchmarks compartidos por Alibaba.
Benchmarks compartidos por Alibaba.
Parámetros. Los parámetros son todas las variables internas que un modelo aprende durante su entrenamiento. Dicho de otro modo, es el conocimiento que el modelo ha obtenido de los datos con los que se ha entrenado y le permite interpretar nuestras peticiones y generar sus respuestas. En teoría, cuantos más parámetros, el modelo tendrá más y mejores capacidades. También implica que necesita más potencia computacional tanto para entrenar como para ejecutar el modelo.
Más no significa mejor. El discurso de los parámetros recuerda al de los megapíxeles con las primeras cámaras. Una sensor de 100 megapíxeles hará fotos más grandes que un sensor de 10, pero hay otros factores cruciales que afectan a la calidad de imagen como el tamaño del sensor o la luminosidad de la lente.
Datos de calidad. Más parámetros se pueden traducir en más capacidad de aprendizaje y más capacidad de resolución de tareas complejas, siempre y cuando se hayan usado datos de entrenamiento de calidad. Resulta obvio: un modelo de lenguaje que haya sido entrenado con datos redundantes, incorrectos o sesgados aprenderá y seguirá reproduciendo esos errores en su funcionamiento.
Hay más. En 2022, el laboratorio DeepMind de Google, descubrió que muchos modelos estaban sobredimensionados en parámetros pero subentrenados en datos. Para demostrarlo crearon el modelo Chinchilla con "sólo" 70.000 millones de parámetros, pero cuatro veces más datos. El resultado fue que superó a Gopher, un modelo con cuatro veces más parámetros.
Arquitectura. La arquitectura del modelo es otro factor decisivo de cara a conseguir un modelo eficiente; no es lo mismo una arquitectura estándar que obliga al modelo a usar toda su red neuronal, que una como Mixture of Experts que se compone de muchas redes más pequeñas. Sería algo así como tener un comité de expertos cada uno con una especialidad. De esta forma, el modelo puede elegir a su experto para cada consulta y no tener que usar toda la red. Por ejemplo, con esta técnica, Mistral logra usar sólo una fracción de sus parámetros y así es más rápido y barato de ejecutar.
Imagen | Markus Winkler, vía Pexels
utm_campaign=09_Sep_2025"> Amparo Babiloni .